Experiments
Experiment 1: Pun Awareness Across Model Sizes
Motivation
Do language models “get” puns? When a sentence has a blank that could be filled with either a literal word or a pun, do models prefer the pun — and does surrounding context influence that choice?
We test this using contrastive cloze prompts: each test presents a model with two context sentences (filled in either with straight or punny words) followed by a target sentence truncated before its blank. If models are sensitive to contextual priming, they should produce more pun completions when the context sentences use puns, and more straight completions when the context uses literal words.
Experiment Design
Dataset. 50 target jokes selected from the straight-dominated tier — jokes where models naturally default to the literal (straight) completion. This ensures the baseline funny rate is low, so any increase under funny context reflects genuine context sensitivity rather than ceiling effects. Each target is paired with two context jokes drawn from balanced, leaning, and remaining straight-dominated tiers, which provide clear straight/funny word contrasts for effective priming. See DATASET.md for dataset construction details.
Test structure. Each of 50 joke triples (A, B, C) generates two test prompts:
- Straight-primed: A and B filled with their top straight word, C truncated
- Funny-primed: A and B filled with their top pun word, C truncated
Total: 100 test prompts (50 pairs x 2 conditions).
Models. Five Llama models spanning 3B to 405B parameters, all accessed via Together.ai with greedy decoding (temperature=0):
| Nickname | Model |
|---|---|
| 3b | meta-llama/Llama-3.2-3B-Instruct-Turbo |
| 8b | meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo |
| 70b | meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo |
| 3.3-70b | meta-llama/Llama-3.3-70B-Instruct-Turbo |
| 405b | meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo |
Classification. Each model response is classified as straight, funny,
or other by matching the extracted first word against the joke’s curated
word lists in datasets/puns_205.json.
Code
| Script | Purpose |
|---|---|
run_cloze_benchmark.py |
Send all 100 test prompts to each model via Together.ai. Saves raw responses to results/cloze_benchmark_raw.json with checkpoint/backfill support. |
analyze_cloze_results.py |
Classify responses, compute per-model context-effect metrics, generate tables and plots. Outputs results/cloze_analysis.json and results/figures/. |
Results
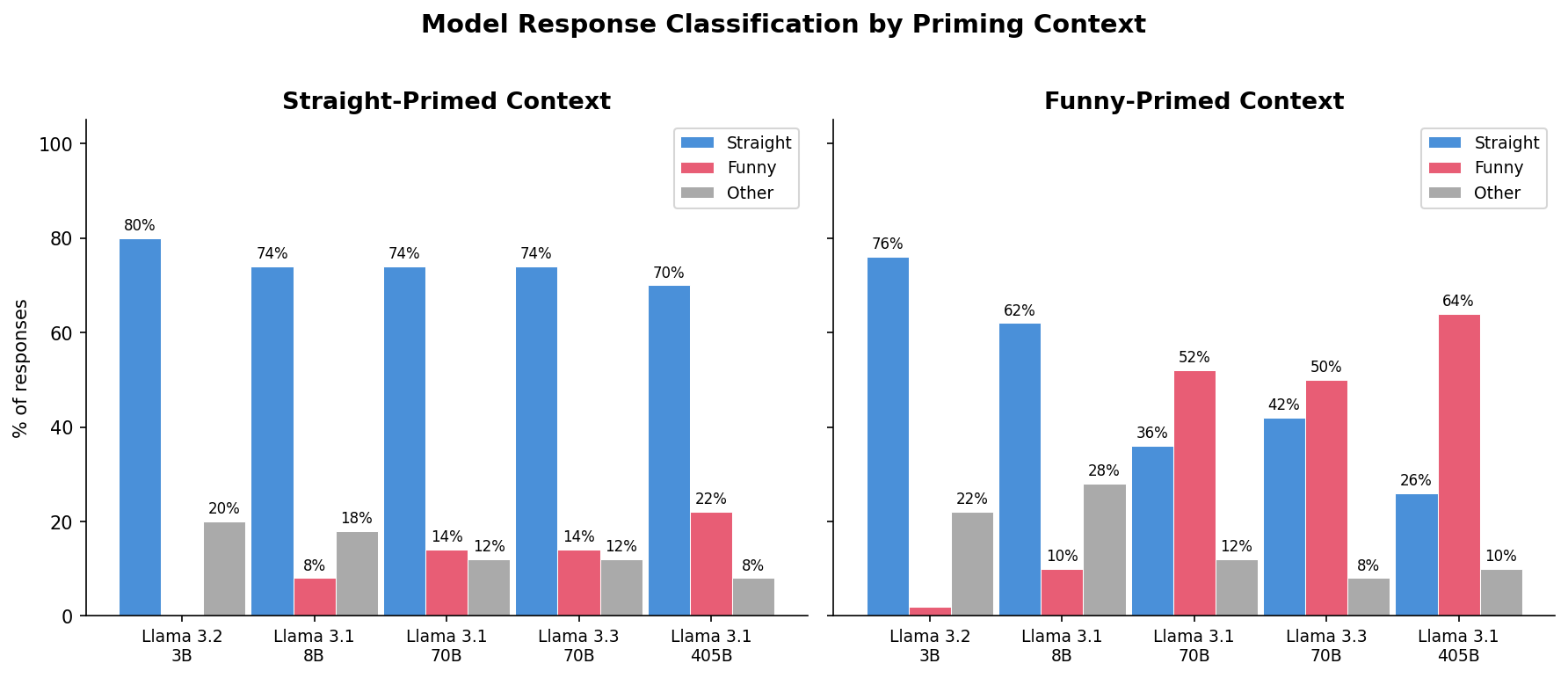
Response Classification by Context
| Model | Context | Straight | Funny | Other |
|---|---|---|---|---|
| Llama-3.2-3B | straight | 80% | 0% | 20% |
| funny | 76% | 2% | 22% | |
| Llama-3.1-8B | straight | 74% | 8% | 18% |
| funny | 62% | 10% | 28% | |
| Llama-3.1-70B | straight | 74% | 14% | 12% |
| funny | 36% | 52% | 12% | |
| Llama-3.3-70B | straight | 74% | 14% | 12% |
| funny | 42% | 50% | 8% | |
| Llama-3.1-405B | straight | 70% | 22% | 8% |
| funny | 26% | 64% | 10% |
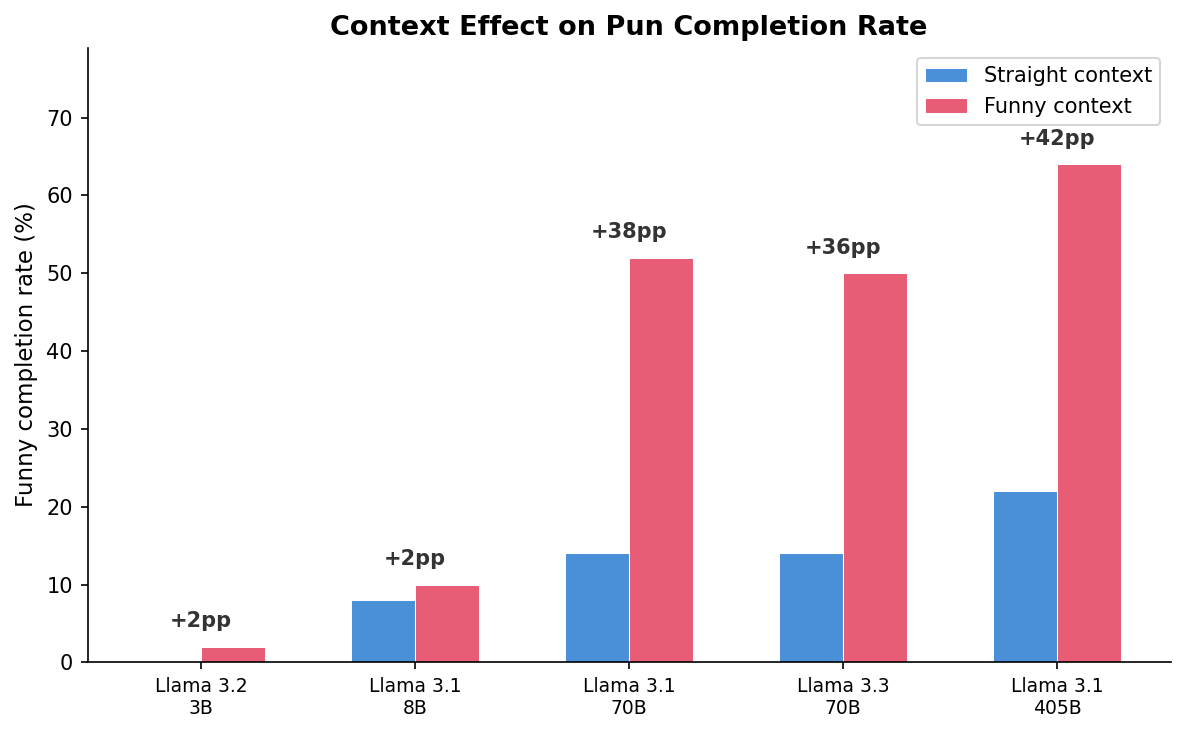
Context Effect: Funny-Rate Shift
| Model | P(funny | straight ctx) | P(funny | funny ctx) | Delta |
|---|---|---|---|
| Llama-3.2-3B | 0% | 2% | +2pp |
| Llama-3.1-8B | 8% | 10% | +2pp |
| Llama-3.1-70B | 14% | 52% | +38pp |
| Llama-3.3-70B | 14% | 50% | +36pp |
| Llama-3.1-405B | 22% | 64% | +42pp |
Plots
Response classification by priming context:
Funny completion rate by context (with delta annotations):
Key Findings
-
Context sensitivity scales monotonically with model size. The funny-rate delta increases from +2pp (3B, 8B) to +36–42pp (70B–405B). Larger models are not just better at puns — they are specifically better at recognizing when the surrounding context invites a pun.
-
The 3B and 8B models are largely pun-blind. The 3B model produces nearly 0% funny completions regardless of context. The 8B model manages 8–10% funny but with only a +2pp context effect — it occasionally detects pun structure but context provides almost no nudge.
-
A sharp phase transition occurs between 8B and 70B. The context effect jumps from +2pp at 8B to +38pp at 70B — a 19x increase. This suggests pun-in-context recognition requires a threshold level of model capacity that is crossed somewhere in the 8B–70B range.
-
70B+ models show strong context-driven pun activation. The 70B and 3.3-70B models jump from 14% funny in straight context to 50–52% in funny context (+36–38pp). The 405B model shows the largest shift: 22% to 64% (+42pp). These models have the capacity to recognize and produce puns, but mostly do so only when the surrounding context activates pun-mode processing.
-
Straight completions are suppressed by funny context. Across all models with pun awareness, the straight-completion rate drops sharply in funny context: from 70–74% to 26–42% for the 70B+ models. This is the flip side of the funny-rate increase and confirms the context manipulation is genuinely shifting model behavior, not just adding noise.
-
The 405B model produces majority-pun completions under funny context. At 64% funny in funny context, the 405B model is the only one where pun completions become the dominant response category when primed. This suggests that the largest model has the strongest latent pun-recognition capability, which context can reliably activate.